In un progresso rivoluzionario per i pazienti con paralisi grave, i ricercatori delL'Università della California, Berkeley e l'Università di San Francisco hanno sviluppato una tecnologia innovativa che converte i segnali cerebrali in parlato udibile in tempo reale. Questo rivoluzionariotecnologia di interfaccia cervello-computer (BCI).segna una pietra miliare significativa nell'aiutare coloro che hanno perso la capacità di parlare a ritrovare le naturali capacità di comunicazione.
L'approccio streaming riduce drasticamente i tempi di risposta
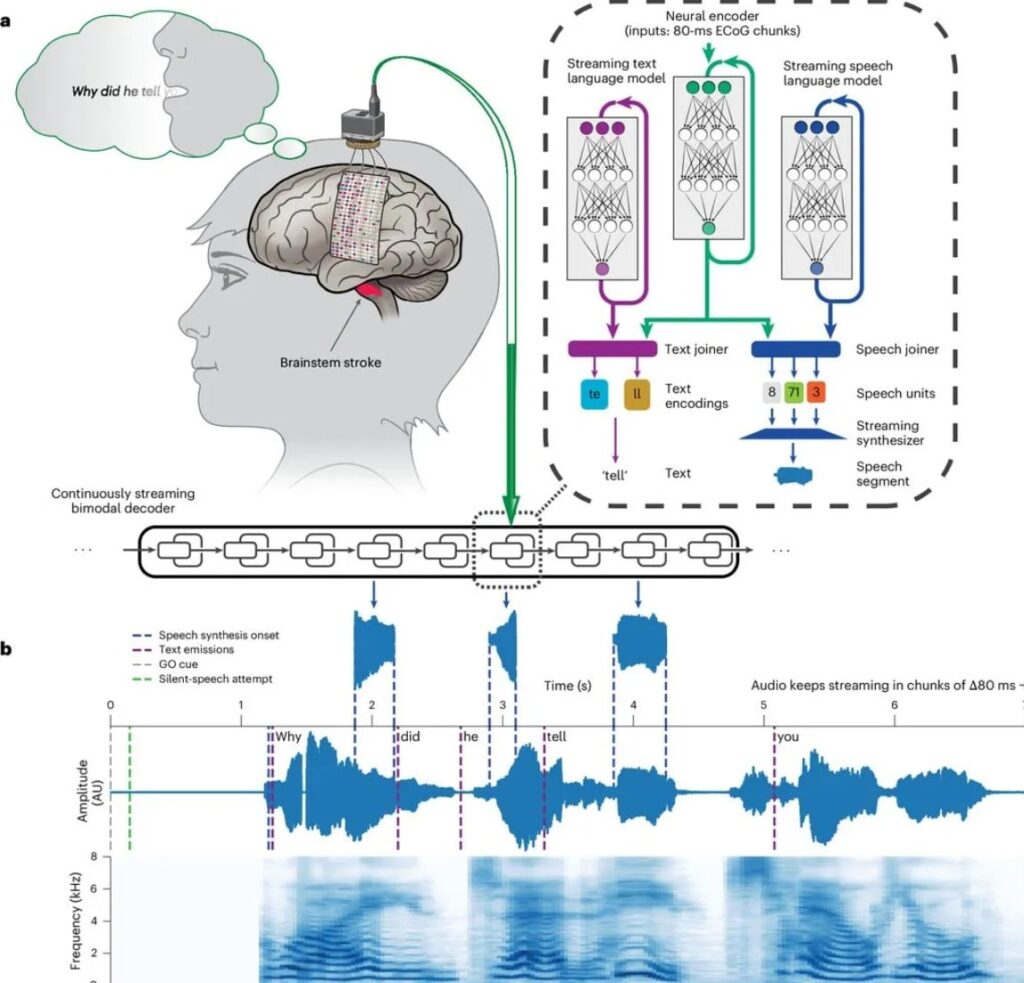
Secondo un articolo pubblicato suIngegneria dell'UC Berkeleysito web, il gruppo di ricerca ha creato unSistema basato sull'intelligenza artificiale che decodifica i segnalidirettamente dalcorteccia motoria del cervello, generando il parlato quasi istantaneamente. Questo "streamingL'approccio rappresenta un notevole miglioramento rispetto ai metodi precedenti.
“Il nostro approccio allo streaming, che sfrutta tecnologie di decodifica vocale simili a quelle utilizzate in Alexa e Siri, può ridurre drasticamente il tempo che intercorre tra l’intento del cervello e l’output vocale”, spiega Gopala Anumanchipalli, co-leader dello studio e assistente professore presso il Dipartimento di Ingegneria Elettrica e Informatica dell’UC Berkeley.

L'impatto di questol'incremento della velocità è notevole. Il cuore della nuova tecnologia è risolvere il problemaproblema di latenza della tradizionale decodifica vocale BCI.Mentre la tecnica precedente richiedeva circa8 secondi per decodificare una singola frase, il nuovo metodo può restituire la prima sillaba all'interno1 secondodopo che il paziente intende parlare.
Risultati nel mondo reale: esperienza della paziente Ann
L’efficacia della tecnologia è stata dimostrata attraverso il lavoro con una paziente identificata come Ann, che era in grado di generare un linguaggio quasi naturale semplicemente “pensando” frasi senza vocalizzazione.
L’approccio innovativo del team alla generazione vocale rende questa tecnologia particolarmente personale.Kaylo Littlejohn, co-primo autore dello studio e dottorando presso l'Università di Berkeley, ha detto che la squadra ha utilizzato unModello di sintesi vocale preaddestrato dall'intelligenza artificialeper simulare la voce del paziente prima dell'infortunio per rendere l'output più personalizzato.
Versatilità e adattabilità
La ricerca dimostra un’impressionante compatibilità tra diversi dispositivi di acquisizione del segnale cerebrale, inclusi array di microelettrodi e sensori EMG facciali, indicando ampie applicazioni potenziali in vari contesti clinici.

La cosa forse più impressionante è che il sistema mostra notevoli capacità di generalizzazione. Quando la paziente Ann tentò di "parlare,“26 parole non sono state incluse nei dati di addestramento, in particolare parole dell'alfabeto fonetico NATO come "Alpha" e"Bravo." La modella ha decodificato accuratamente le sue intenzioni.
“Ciò dimostra che il nostro sistema non si basa solo sulla corrispondenza dei modelli, ma in realtà apprende le regole del discorso di composizione,”osserva Cheol Jun Cho, un altro co-primo autore e dottorando. "Questa capacità getta le basi per futuri miglioramenti nel tono, nell'intonazione e in altre caratteristiche dell'espressione vocale"
Direzioni future
La paziente Ann riferisce che questo nuovo approccio le dà maggiore controllo ed espressione di sé rispetto alle sue precedenti esperienze sperimentali nel 2023.
Guardando al futuro, il team di ricerca prevede di perfezionare i propri algoritmi per migliorare la naturalezza del parlato e l’espressione emotiva, esplorando al contempo applicazioni per una gamma più ampia di scenari clinici.
Questa tecnologia di interfaccia neurale rappresenta un progresso significativo nelle tecnologie di comunicazione assistiva. Dimostra come l’intelligenza artificiale può essere sfruttata per ripristinare capacità umane fondamentali come la parola a coloro che le hanno perse a causa di lesioni o malattie.