浙江大学と上海AIラボが発表作成-MMBench、特別に設計されたベンチマーク現実世界のシナリオでマルチモーダルな創造性を評価する。このツールは、今日の最先端のクリエイティブな能力に関する驚くべき洞察を明らかにします。AIモデルという発見も含めて、GPT-4.5の創造的能力は人よりも遅れているGPT-4o多くのシナリオで。
従来の AI 評価を超えて
GPT-4.5 は広く賞賛されていますが、日常の Q&A やさまざまな創造的なタスクにおける印象的な文脈の一貫性により、研究者は重要な疑問を特定しました。どこまさに「」です創造性の天井" のマルチモーダル大規模言語モデル (MLLM)?
課題は、複雑なシナリオにおける創造性を測定することでした。既存のベンチマークは、AI モデルが真に創造的な洞察を生み出すかどうかを定量化するのに苦労しており、多くのテスト シナリオは単純すぎて、現実世界の創造的思考の状況でこれらのモデルがどのように機能するかを反映できません。
作成-MMBench「」を総合的に評価することで、このギャップを解決します。視覚的創造的知性」 4 つの主要なタスク カテゴリにわたって、51 のきめ細かいタスク、そして765挑戦的なテストケース。

ビジュアルクリエイティブインテリジェンスが重要な理由
創造的なインテリジェンスは伝統的に最も困難な側面でした。AI評価し開発すること。明確な正解か不正解がある分析タスクとは異なり、創造性には、多様な状況にわたって斬新かつ適切な解決策を生み出すことが含まれます。
現在の MLLM ベンチマーク:MMベンチそしてムワネス、マルチモーダル AI との現実のやり取りでよくある創造的な課題を無視しながら、主に分析または実践的なタスクに焦点を当てます。 Creation-MMBench は、多様なコンテンツと単一画像と複数画像の問題の両方を含む複雑なシナリオを特徴とすることで、他と一線を画しています。
例えば、ベンチマークはモデルに次のことを課します。
- 説得力のある博物館展示物の解説を作成する
- 人物の写真をもとに感情的でストーリー性のあるエッセイを書く
- ミシュランのシェフが料理の写真を解釈して、微妙な料理のガイドを作成します
これらのタスクでは、視覚的なコンテンツの理解、文脈の適応、創造的なテキストの生成を同時に習得する必要がありますが、これらの能力は既存のベンチマークでは包括的に評価されることはほとんどありません。
Creation-MMBench の厳格な評価フレームワーク

このベンチマークには、次の 4 つの主要なタスク カテゴリが含まれています。
- 創作: 詩、対話、物語、物語の構築を通じて芸術的表現を評価します。
- 日常の機能的な文章: ソーシャルメディア、公共イニシアチブ、電子メール、実際の質問に関する実践的なライティングをテストします。
- プロフェッショナルなファンクショナルライティング: インテリア デザイン、授業計画、風景の説明などの専門的な文章を評価します。
- マルチモーダルな理解と創造: 文書分析と写真鑑賞を通じて視覚とテキストの統合を検討します
Creation-MMBench の特徴はその複雑さです。約 30 のカテゴリにわたる数千のクロスドメイン画像が組み込まれており、タスクごとに最大 9 つの画像入力をサポートします。テストのプロンプトは包括的で、多くの場合 500 語を超え、豊かで創造的なコンテキストを提供します。
クリエイティブの品質を数値化する二重評価システム
クリエイティブの品質を客観的に定量化するために、チームは二重評価アプローチを導入しました。
- ビジュアルファクトスコア (VFS): 情報を捏造することなく、モデルが画像の詳細を正確に読み取ることを保証します。
- 褒美: ビジュアルコンテンツと組み合わせて、モデルの創造的能力とプレゼンテーションスキルを評価します。
評価プロセスでは、GPT-4o を判断モデルとして使用し、評価基準、画面の内容、模範回答を考慮して、模範回答と参考回答の間の相対的な好みの評価を提供します。
信頼性を検証するために、人間のボランティアがサンプルの 13% を手動で評価し、GPT-4o が人間の好みと強い一貫性を示していることを確認しました。
ベンチマーク結果: クローズド モデルとオープンソース モデル
研究チームは、GPT-4o、Gemini シリーズ、Claude 3.5、Qwen2.5-VL や InternVL などのオープンソース モデルを含む、VLMEvalKit ツールチェーンを使用して 20 以上の主流 MLLM を評価しました。
主な調査結果:
- ジェミニ-2.0-プロマルチモーダルなクリエイティブライティング、特に日常の機能的なライティングタスクで GPT-4o を上回りました。
- GPT-4.5全体的なパフォーマンスが両方よりも劣っていたGemini-Pro および GPT-4o、特にマルチモーダルコンテンツの理解と作成において優れていましたが、
- 次のようなオープンソース モデルクウェン2.5-VL-72BそしてインターンVL2.5-78B-MPOクローズドソースモデルに匹敵するクリエイティブな能力を実証したが、それでもパフォーマンスにギャップがあった
カテゴリ固有の洞察:
- プロフェッショナルな機能的ライティング専門的な知識と視覚的な内容の深い理解に対する要求が高いため、最も困難であることが判明しました
- 全体的なパフォーマンスが低いモデルでも、状況や視覚コンテンツがより単純な、日常の社会生活に関連する日常タスクでは優れている可能性があります。
- ほとんどのモデルは、マルチモーダルな理解と作成タスクで高い視覚的事実スコアを達成しましたが、視覚的なコンテンツに基づいた再現には苦労しました
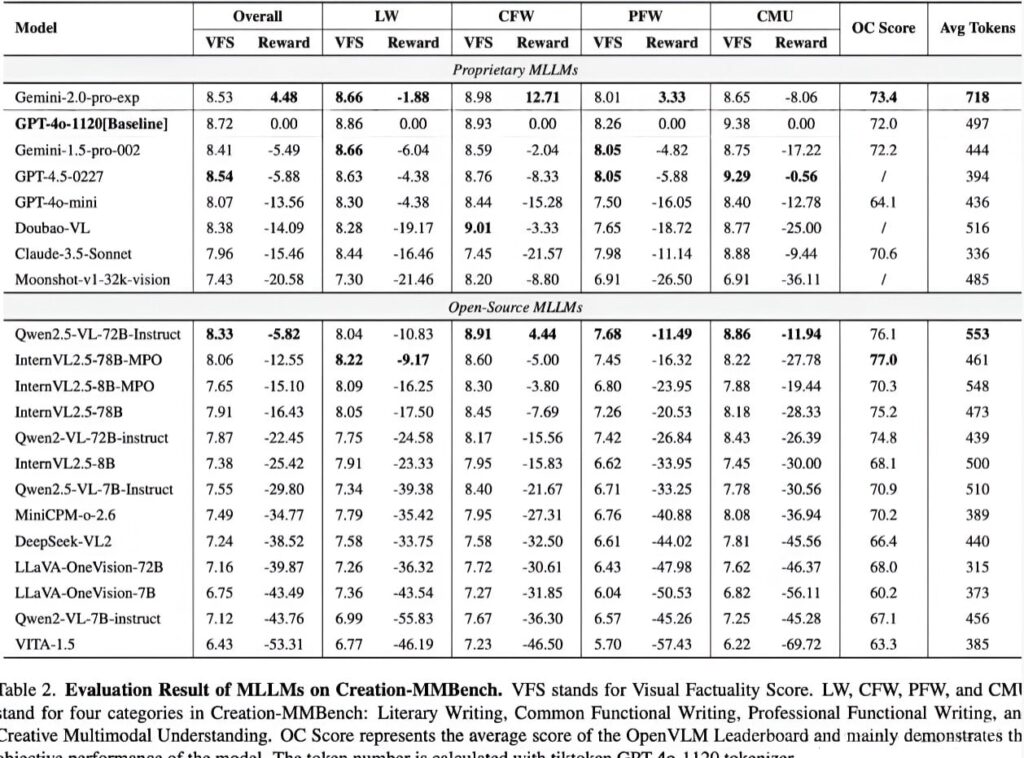
プロフェッショナルなファンクショナルライティングは、専門的な知識と深い視覚的理解を必要とするため、タスクカテゴリの中で最も困難であることが判明しました。対照的に、日常的な関数記述タスクでは、一般的な社会シナリオとの類似性により、モデル全体で高いパフォーマンスが見られました。

視覚的な微調整の影響
モデルの機能をさらに理解するために、チームは、と呼ばれるテキストのみのバージョンを作成しました。作成-MMBench-TOここで、GPT-4o は画像コンテンツを詳細に説明しました。
テキストのみの評価では次のことがわかりました。
- クローズドソースの言語モデルは、オーサリング能力においてオープンソースの言語モデルをわずかに上回りました。
- GPT-4o は、テキストのみのバージョンでより高い創造的報酬スコアを達成しました。これはおそらく、視覚的な理解の制約のない発散的思考により重点を置いたことによるものと考えられます。
- 視覚的な命令を微調整したオープンソースのマルチモーダル モデルは、Creation-MMBench-TO でのパフォーマンスが基本言語モデルよりも一貫して悪かった。
これは、視覚的な指示を微調整すると、長いテキストを理解して拡張コンテンツを作成するモデルの能力が制限され、その結果、視覚的な事実スコアと創造的な報酬が低下する可能性があることを示唆しています。

現実世界の例: ソフトウェアエンジニアリングの解釈
定性的調査では、モデルが特定の専門的タスクを処理する方法に大きな違いがあることが明らかになりました。
- クウェン2.5-VLドメイン知識が不十分なためにスイムレーン図をデータ フロー図と誤認し、不正確な分析につながった
- GPT-4oこのエラーを回避し、正確な図の解釈を備えたより専門的で構造化された言語を提供しました
これ例のハイライト専門的な業務における分野固有の知識と詳細なイメージの理解が非常に重要であり、オープンソース モデルとクローズドソース モデルの間には依然としてギャップがあることが実証されています。

結論
Creation-MMBench、詳細は以下で入手可能GitHubは、現実的なシナリオにおけるマルチモーダル大規模モデルの創造的な能力を評価する際の大きな進歩を示しています。 51 の詳細なタスクと包括的な評価基準にわたる 765 のインスタンスにより、モデルのパフォーマンスについて前例のない洞察が得られます。
ベンチマークは現在、VLMEvalKit、ワンクリック評価をサポートし、クリエイティブなタスクにおけるモデルのパフォーマンスを総合的に評価します。これにより、モデルが視覚的な入力に基づいて魅力的なストーリーを効果的に伝えることができるかどうかを判断することがこれまでより簡単になります。





![iPhone から PC にワイヤレスでファイルを転送する方法 [完全ガイド]](https://elsefix.com/statics/image/placeholder.png)


