Zhejiang Universiteit en Shanghai AI Lab hebben vrijgegevenCreatie-MMBench,een benchmark die speciaal is ontworpen omevalueer multimodale creativiteit in realistische scenario's. Deze tool onthult verrassende inzichten over de creatieve mogelijkheden van de meest geavanceerde van vandaagAI-modellen, inclusief de ontdekking datGPT-4.5's creatieve vermogens blijven achter bij die vanGPT-4oin veel scenario's.
Verder gaan dan traditionele AI-evaluatie
Terwijl GPT-4.5 alom wordt geprezenvanwege de indrukwekkende contextuele samenhang in alledaagse vragen en antwoorden en verschillende creatieve taken, identificeerden onderzoekers een kritische vraag:Waaris precies de “creativiteit plafond" vanmultimodale grote taalmodellen (MLLM's)?
De uitdaging is het meten van creativiteit in complexe scenario's. Bestaande benchmarks hebben moeite om te kwantificeren of een AI-model echt creatieve inzichten oplevert, waarbij veel testscenario's te simplistisch zijn om weer te geven hoe deze modellen presteren in creatieve denksituaties in de echte wereld.
Creatie-MMBenchpakt deze kloof aan door een uitgebreide evaluatie van “visuele creatieve intelligentie”in vier grote taakcategorieën,51 fijnmazige taken,En765uitdagende testgevallen.

Waarom visuele creatieve intelligentie belangrijk is
Creatieve intelligentie is van oudsher het meest uitdagende aspect vanAIevalueren en ontwikkelen. In tegenstelling tot analytische taken met duidelijke goede of foute antwoorden, gaat creativiteit gepaard met het genereren van nieuwe, maar passende oplossingen in verschillende contexten.
Huidige MLLM-benchmarks, zoalsMMBenchEnMmwanheidrichten zich primair op analytische of praktische taken, terwijl ze de creatieve uitdagingen over het hoofd zien die vaak voorkomen in real-life interacties met multimodale AI. Creation-MMBench onderscheidt zich door complexe scenario's met uiteenlopende inhoud en problemen met zowel één als meerdere afbeeldingen aan te bieden.
Bijvoorbeeld, daagt de benchmark modellen uit om:
- Genereer boeiend commentaar op museumtentoonstellingen
- Schrijf emotionele, verhaalgedreven essays op basis van foto's van mensen
- Creëer genuanceerde culinaire begeleiding als een Michelin-chef die voedselfoto's interpreteert
Deze taken vereisen gelijktijdige beheersing van het begrijpen van visuele inhoud, contextuele aanpassing en creatieve tekstgeneratie – vaardigheden die bestaande benchmarks zelden volledig beoordelen.
Het rigoureuze evaluatiekader van Creation-MMBench

De benchmark kent vier hoofdtaakcategorieën:
- Literaire creatie: Evalueert artistieke expressie door middel van gedichten, dialogen, verhalen en narratieve constructie
- Dagelijks functioneel schrijven: Test praktisch schrijven voor sociale media, publieke initiatieven, e-mails en vragen uit het echte leven
- Professioneel functioneel schrijven: Beoordeelt gespecialiseerd schrijven voor interieurontwerp, lesplanning en landschapsbeschrijvingen
- Multimodaal begrip en creatie: Onderzoekt de visueel-tekstuele integratie door middel van documentanalyse en fotografiewaardering
Wat Creation-MMBench onderscheidt, is de complexiteit ervan. Het bevat duizenden domeinoverschrijdende afbeeldingen in bijna 30 categorieën en ondersteunt maximaal 9 afbeeldingsinvoer per taak. Testprompts zijn uitgebreid en bevatten vaak meer dan 500 woorden om een rijke, creatieve context te bieden.
Dubbel evaluatiesysteem kwantificeert creatieve kwaliteit
Om de creatieve kwaliteit objectief te kwantificeren, implementeerde het team een dubbele evaluatieaanpak:
- Visuele feitenscore (VFS): Zorgt ervoor dat het model afbeeldingsdetails nauwkeurig leest zonder informatie te verzinnen
- Beloning: Evalueert het creatieve vermogen en de presentatievaardigheden van het model in combinatie met visuele inhoud
Het evaluatieproces gebruikt GPT-4o als beoordelingsmodel, waarbij rekening wordt gehouden met de evaluatiecriteria, scherminhoud en modelreacties om relatieve voorkeursbeoordelingen te geven tussen modelantwoorden en referentieantwoorden.
Om de betrouwbaarheid te verifiëren, evalueerden menselijke vrijwilligers handmatig 13% van de monsters, wat bevestigde dat GPT-4o een sterke consistentie vertoont met menselijke voorkeuren.
Benchmarkresultaten: gesloten versus open source-modellen
Het onderzoeksteam evalueerde meer dan twintig reguliere MLLM's met behulp van de VLMEvalKit-toolchain, waaronder GPT-4o, de Gemini-serie, Claude 3.5 en open-sourcemodellen zoals Qwen2.5-VL en InternVL.
Belangrijkste bevindingen:
- Gemini-2.0-Propresteerde beter dan GPT-4o bij multimodaal creatief schrijven, vooral bij dagelijkse functionele schrijftaken
- GPT-4.5toonden zwakkere algemene prestaties dan beideGemini-Pro en GPT-4o,hoewel het specifiek uitblonk in het begrijpen en creëren van multimodale inhoud
- Open-sourcemodellen zoalsQwen2.5-VL-72BEnInternVL2.5-78B-MPOtoonden creatieve mogelijkheden aan die vergelijkbaar zijn met closed-sourcemodellen, maar vertoonden nog steeds een prestatiekloof
Categoriespecifieke inzichten:
- Professioneel functioneel schrijvenbleek de grootste uitdaging vanwege de hoge vraag naar gespecialiseerde kennis en een diepgaand begrip van de visuele inhoud
- Modellen met zwakkere algemene prestaties kunnen nog steeds uitblinken in alledaagse taken die verband houden met het dagelijkse sociale leven, waar situaties en visuele inhoud eenvoudiger zijn.
- De meeste modellen behaalden hoge visuele feitelijke scores op multimodaal begrip en creatietaken, maar hadden moeite met recreatie op basis van visuele inhoud
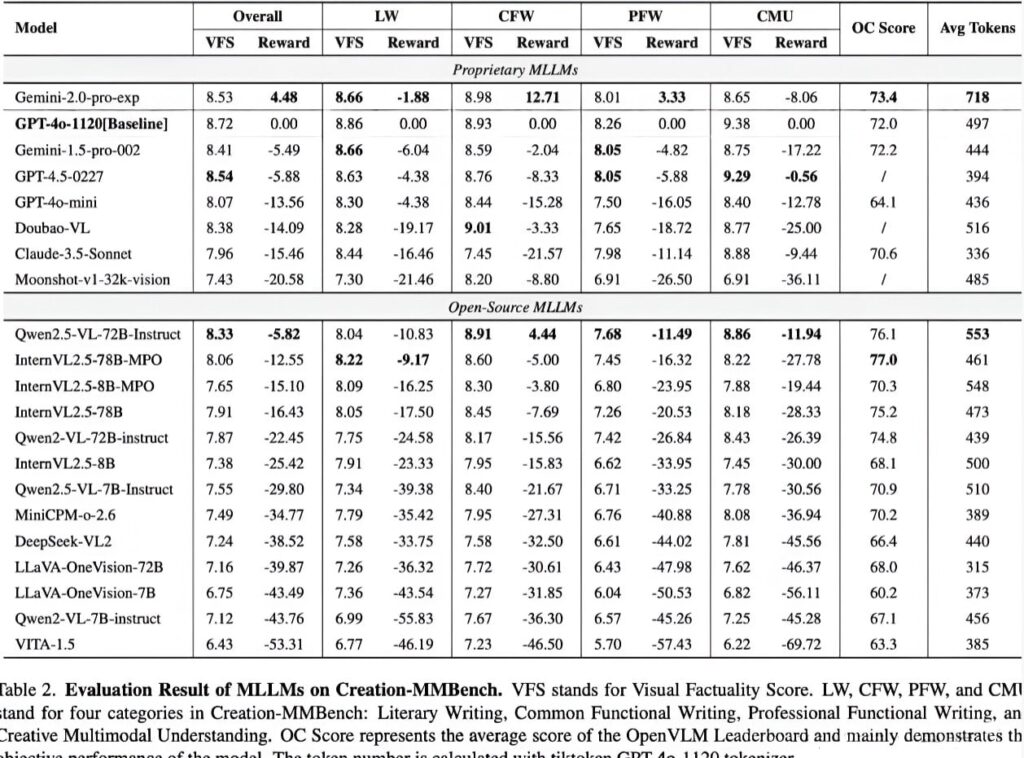
Professioneel functioneel schrijven bleek de meest uitdagende taakcategorie vanwege de vraag naar gespecialiseerde kennis en diep visueel begrip. Daarentegen lieten alledaagse functionele schrijftaken hogere prestaties zien in alle modellen vanwege hun gelijkenis met algemene sociale scenario's.

De impact van visuele afstemming
Om de modelmogelijkheden verder te begrijpen, heeft het team een versie met alleen tekst gemaakt, genaamdCreatie-MMBench-TO, waar GPT-4o de beeldinhoud in detail beschreef.
Uit de alleen-tekstevaluatie bleek:
- Gesloten-source taalmodellen presteerden iets beter dan open-source-talen wat betreft schrijfmogelijkheden
- GPT-4o behaalde hogere creatieve beloningsscores op de tekstversie, mogelijk door zich meer te concentreren op divergent denken zonder beperkingen op het gebied van visueel begrip.
- Open-source multimodale modellen met verfijnde afstemming van visuele instructies presteerden consistent slechter op Creation-MMBench-TO dan hun basistaalmodel.
Dit suggereert dat het afstemmen van visuele instructies het vermogen van een model om langere teksten te begrijpen en uitgebreide inhoud te creëren kan beperken, wat resulteert in lagere visuele feitelijke scores en creatieve beloningen.

Voorbeeld uit de praktijk: interpretatie van software-engineering
Kwalitatief onderzoek bracht significante verschillen aan het licht in de manier waarop modellen met specifieke professionele taken omgingen:
- Qwen2.5-VLidentificeerde een zwembaandiagram ten onrechte als een gegevensstroomdiagram vanwege onvoldoende domeinkennis, wat leidde tot een onjuiste analyse
- GPT-4overmeed deze fout en zorgde voor meer professionele, gestructureerde taal met nauwkeurige diagraminterpretatie
Ditvoorbeeld hoogtepuntenhet cruciale belang van domeinspecifieke kennis en gedetailleerd beeldbegrip bij professionele taken, wat de aanhoudende kloof tussen open-source- en gesloten-sourcemodellen aantoont.

Conclusie
Creatie-MMBench, metdetails beschikbaar opGitHub, vertegenwoordigt een aanzienlijke vooruitgang bij het evalueren van de creatieve capaciteiten van multimodale grote modellen in realistische scenario's. Met 765 instanties die 51 gedetailleerde taken omvatten en uitgebreide evaluatiecriteria, biedt het ongekend inzicht in de modelprestaties.
De benchmark is nu geïntegreerd inVLMEvalKit, ter ondersteuning van evaluatie met één klik om de prestaties van elk model bij creatieve taken uitgebreid te beoordelen. Dit maakt het eenvoudiger dan ooit om te bepalen of uw model op basis van visuele input effectief een boeiend verhaal kan vertellen.